
OpenAI embeddings present a new way to describe texts, so that those texts can be ranked or classified based on their meaning. This is a new technology bound to change how we work with text data today.
To give a concrete example, most current solutions search for substrings or keywords. With embeddings we can search for semantic meaning, and not just syntax.
In the following tutorial, we will use embeddings to search and rank texts based on their natural language meaning, and provide code samples along the way. Also, we will not be using any fancy tools, and just stick to the basics so that anyone can follow along.
What Are Embedding Vectors and Vector Databases?
An embedding vector is just a list of decimal values, which describe a given text. For example, the word "Dog" may be represented as [1.5, 2.3, 3.8], which may seem meaningless at first glance. The vector starts to make sense if we compare it to another vector for "Canine", which may be [1.5, 2.2, 3.7]. Notice how the two vectors are very similar even though the texts are nothing like each other.
OpenAI gives us vectors (or just lists of decimal values), which are all of the same size: 1536 values. These vectors capture the meaning of the texts.
A vector database is a collection of texts, with their vectors stored in a database table, such as MySQL. This database can later be used ot quickly search or rank results based on a search query.
OpenAI Simple Embeddings Client
Below is a simple API client for OpenAI's embeddings function. We will use it later to get embedding vectors for our database and also for our search query.
The entire concept only needs a single API endpoint from OpenAI: /embeddings
Side note: please remember to sanitize your text input through OpenAI moderations in a production setting.
<?php
class OpenAIEmbeddingSimpleClient {
private static $open_ai_key = '<your openai key here>';
private static $open_ai_url = 'https://api.openai.com/v1'; //current version of the API endpoint
public static function embeddings($text, $model='text-embedding-ada-002') {
//create message to post
$message = new stdClass();
$message -> input = $text;
$message -> model = $model;
$result = self::_sendMessage('/embeddings', json_encode($message));
return $result;
}
private static function _sendMessage($endpoint, $data = '', $method = 'post', $contentType = 'application/json') {
$apiEndpoint = self::$open_ai_url.$endpoint;
$curl = curl_init();
if($method == 'post') {
$params = array(
CURLOPT_URL => $apiEndpoint,
CURLOPT_SSL_VERIFYHOST => false,
CURLOPT_SSL_VERIFYPEER => false,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_MAXREDIRS => 10,
CURLOPT_TIMEOUT => 90,
CURLOPT_HTTP_VERSION => CURL_HTTP_VERSION_1_1,
CURLOPT_CUSTOMREQUEST => "POST",
CURLOPT_NOBODY => false,
CURLOPT_HTTPHEADER => array(
"content-type: ".$contentType,
"accept: application/json",
"authorization: Bearer ".self::$open_ai_key
)
);
curl_setopt_array($curl, $params);
curl_setopt($curl, CURLOPT_POSTFIELDS, $data);
} else if($method == 'get') {
$params = array(
CURLOPT_URL => $apiEndpoint . ($data!=''?('?'.$data):''),
CURLOPT_SSL_VERIFYHOST => false,
CURLOPT_SSL_VERIFYPEER => false,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_MAXREDIRS => 10,
CURLOPT_TIMEOUT => 90,
CURLOPT_HTTP_VERSION => CURL_HTTP_VERSION_1_1,
CURLOPT_CUSTOMREQUEST => "GET",
CURLOPT_NOBODY => false,
CURLOPT_HTTPHEADER => array(
"content-type: ".$contentType,
"accept: application/json",
"authorization: Bearer ".self::$open_ai_key
)
);
curl_setopt_array($curl, $params);
}
$response = curl_exec($curl);
curl_close($curl);
$data = json_decode($response, true);
if(!is_array($data)) return array();
return $data;
}
}
Fetching Vectors and Storing Them In Our Database
First, let's create a MySQL database table, where we will store our texts and vectors.
CREATE TABLE `vectors` (
`id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`text` TEXT NULL DEFAULT NULL,
`embedding` TEXT NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
)
ENGINE=InnoDB;
Then, using the above API client, we can connect to OpenAI, and create our vector database, which looks like the following:

We use the `embedding` column with type TEXT to store the vectors as plain text, however in a production setting we would probably use a BLOB and store the values as 8 byte floating point values. This would greatly increase efficiency, and would also reduce our database size by a factor of 3. However, we can get good performance even with this naive approach.
It is worth noting there are other tools available, which can manage vectors natively - but these normally come with a price tag.
How Much Does The OpenAI Embeddings API Cost?
OpenAI charges $0.0001 per 1K tokens, and 1K tokens are roughly 4k characters of text. To put this in perspective, it would cost just two cents to get embeddings for a 100 page book.
This is also a one-time cost, which does not have to be repeated if the embeddings are stored in a database. If your texts start to get too long, consider using text rephrasing capabilities.
Example Code For Searching Our Vector Database
Below is a script, which fetches an embedding for our test text "canine", and then sorts all of our existing texts based on how close in meaning they are to this text.
<?php
include_once('OpenAIEmbeddingSimpleClient.php');
//establish DB connection
$GLOBALS['db_connection'] = mysqli_connect('localhost', 'root', '', 'test') or die("db connection error");
mysqli_query($GLOBALS['db_connection'], "SET NAMES 'utf8'");
//"canine" embedding, test text
$openAIEmbedding = OpenAIEmbeddingSimpleClient::embeddings('canine');
$compareEmbedding = $openAIEmbedding['data'][0]['embedding'];
foreach($compareEmbedding as $ind => $v) {
$compareEmbedding[$ind] = doubleval($v);
}
//fetch our stored vector database from MySQL/MariaDB
$res = executeQuery('select * from vectors;');
$list = [];
while($row = fetchArray($res)) {
$similarityScore = cosineSimilarity(explode(',', $row['embedding']), $compareEmbedding);
$list[] = [
'text' => $row['text'],
'score' => $similarityScore
];
}
usort($list, function($a, $b) {
return $b['score'] <=> $a['score'];
});
print_r($list);
//end of script...
//OpenAI Recommended Algorithm For Comparing Embeddings
function cosineSimilarity($vector1, $vector2) {
$dotProduct = 0.0;
$sqSum1 = 0.0;
$sqSum2 = 0.0;
//Performance hack? Stop after 100 comparisons, depending on your data this may be enough
foreach($vector1 as $ind => $d1) {
$d1 = doubleval($d1);
$d2 = $vector2[$ind];
$dotProduct += $d1 * $d2;
$sqSum1 += $d1 * $d1;
$sqSum2 += $d2 * $d2;
}
return $dotProduct / (sqrt($sqSum1) * sqrt($sqSum2));
}
//DB helper functions
function dbError(){
throw new Exception("db_error:".mysqli_error($GLOBALS['db_connection']));
}
function executeQuery($query){
if (!is_null($query)) {
$resultResource = mysqli_query($GLOBALS['db_connection'], $query);
if (!$resultResource) {
dbError();
}
if(stripos($query, 'insert') === 0) {
return mysqli_insert_id($GLOBALS['db_connection']);
}
return $resultResource;
} else {
throw new Exception("query not set");
}
}
function fetchArray($resultResource){
return mysqli_fetch_array($resultResource, MYSQLI_ASSOC);
}
And the following is what the result looks like, if we have a database of 1k existing texts that we want to rank.
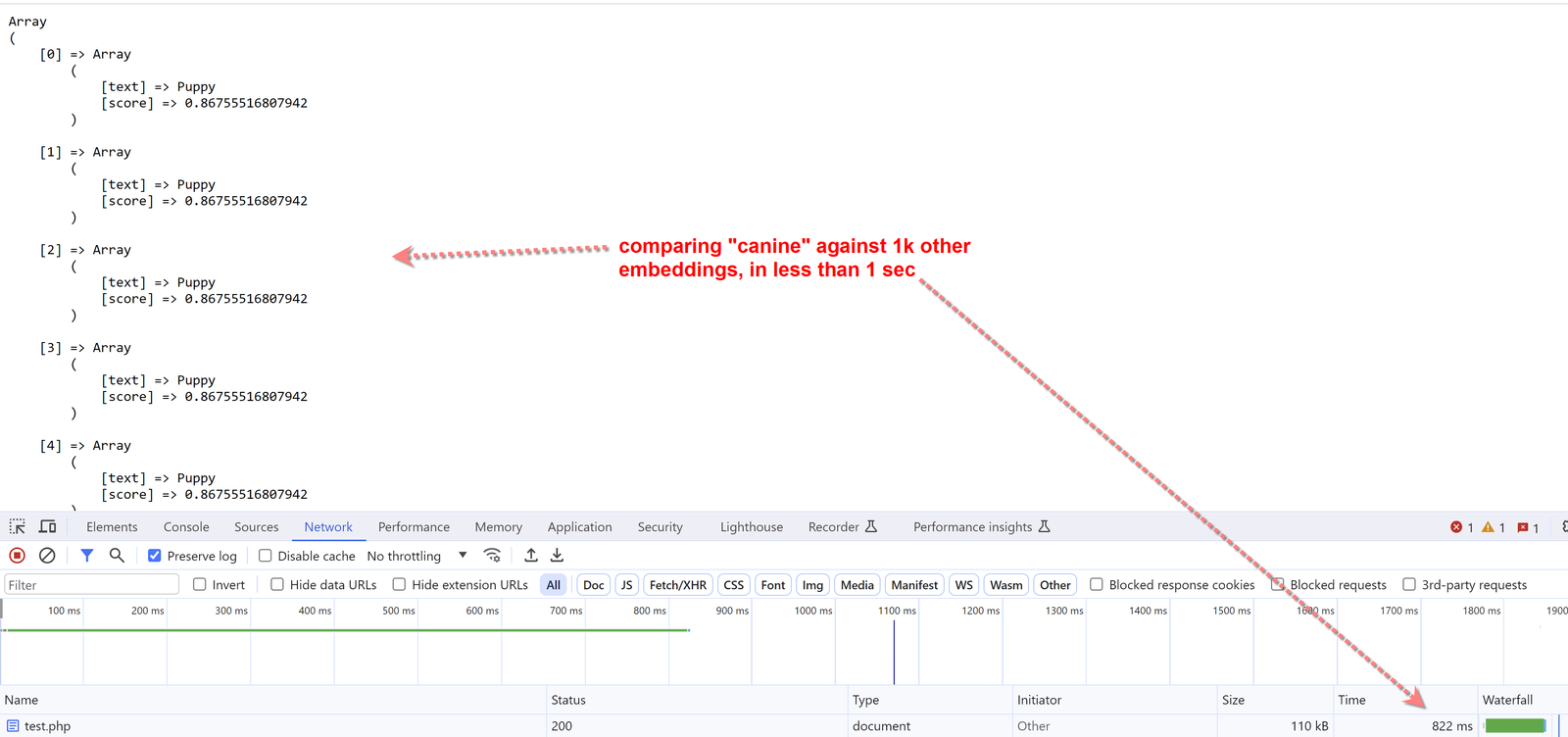
Performance Of Using PHP and MySQL For Vector Databases
We did some test benchmarks of the above implementation, and here are the figures:
- For 1,000 vectors (texts), we are able to rank all of them based on a search query in 0.8 seconds.
- For 10,000 vectors, the same script runs in 7 seconds.
It is important to realize, we managed to work with AI vectors, just by using plain vanilla PHP and MySQL. There are other storage systems available now, which have these structures built in - but these are not necessary to get started.
While doing all of this, we discovered a very nice thing!
We actually do not have to compare all 1536 vector values to still achieve good results!
Specifically, just by comparing the first 100 vector values, the ranking did not change, and we were able to process 10k vectors in under 1 second.
Pro tip: to implement this in a performance setting, the comparison function should accept an extra parameter between 0 and 1, stating how much of the vector should be processed. At least from our tests, we found that we do not always have to compare the entire vector.
Which Comparison Function Is Best
OpenAI recommends to use the cosine similarity algorithm, and we also found it to yield the best results. Another algorithm we tried was the dot product, however we do not recommend it because the performance boost was minimal and the ranking results were considerably worse.
In the above code sample, we implemented the cosine similarity function in PHP, and share it with you here.
Capabilities Of Vector Embeddings
The following are already existing capabilities of using vector embeddings:
- Rank and search (covered in this tutorial)
- Grouping and classification (put similar texts into buckets)
- Recommendation systems (show the user top X results)
- Detect anomalies (check if a given text or dataset has a completely different semantic meaning)
- Statistics and distributions (similar to above, but check if groups of texts fall into normal patterns)
- Image recognition (if we transform an image into text first)
Like with other AI solutions, the challenge still remains for how to collect and format the texts, but this is expected. For example, it may not be worth while to get an embedding for a very long text document, and instead do this on a page-by-page basis, so that when a user does a search, we can forward them to the best matching page within the document.
Detecting anomalies is an especially interesting application, and we wonder if it would be possible to separate fake reviews from real ones. This is another major issue in front of many online businesses today.
Conclusion
Traditional text searching and ranking is based on substrings or keyword search. This has been the dominating methodology for decades, driving all kinds of solutions such as Fuzzy Search, Solr Search and text indexing at the Database level such as MySQL. The biggest challenge of all these systems is, they have a hard time with synonyms and semantic meaning.
In the above tutorial we successfully ranked the words "Puppy" and "Dog" as the top results when searching for "Canine", and we did this by using embedding vectors. The performance is good, and we believe this has the potential to become the next replacement for many search applications.
If this tutorial was helpful, then you'll like the following example, where we teach an AI to fix email address mistypes.

















 and AI: A Business Perspective")
Best guide for PHP for openai embeddings
Thanks for work. This finally allowed me to understand how to do in PHP. I was looking to see if I could implement into MySQL a function to do cosineSimilarity or just dotproduct but it was way too slow. I haven't explored yet writing a custom user defined c function for mysql but doesn't look it is needed till larger datasets required.