
ChatGPT limits both the input (prompt) and output texts, to at most 4096 characters. All texts are split into "tokens", which are on average 4 characters long. Then, based on the number of tokens (both input and output), your OpenAI account will be charged a flat fee of $0.002 (0.2 cents) per 1000 tokens when using GPT-3.5. The newer model "GPT-4 Turbo" has a different price of $0.01/1K input tokens and $0.03/1K output tokens.
For example, let's say we have the following text: "My cat eats food like a boss". This is counted as 7 tokens; it just so happens that each word is at most 4 letters long. In contrast, the following text is 5 tokens long, bause it uses longer words: "Rabbits are fluffy".
The main issue with this model is, you never really know in advance what is the exact number of tokens being passed back and forth. In the article below we'll go over some ways to make estimates and get a feel for how much the cost will be, and we will also provide some helpful tips along the way.
What is The Maximum Character Limit For The Input?
The character limit on ChatGPT 3.5 is 4096. For GPT-4 the limit is 8192, however this is only theoretical, and in practice it will still usually be 4096. Developers report that this is still an issue for the OpenAI API.
Below is a table of the official character and token limits for ChatGPT, and also practical limits being reported by real world developers. It is important to remember, both limits are applied to requests and outputs (character and token limit).
| Version | Official Character Limit (input and output) | Official Token Limit (input and output) | Practical Character Limit (input and output) | Practical Token Limit (input and output) |
|---|---|---|---|---|
| ChatGPT-3.5 | 4096 | 1024 | 4096 | 1024 |
| GPT-4 | 8192 | 2048 | ~4096 | ~1024 |
| GPT-4-Turbo | 512000 | 128000 | tbd | tbd |
The reason for GPT-4 having this limit in practice is usually it will cut short of producing much more text. This may change in the future as the model improves.
Estimating The Number of Tokens
OpenAI provides this online tool to estimate how many "tokens" a given text contains.
Developers often need to make an estimate locally before sending any request to OpenAI, and below is an estimator written in PHP. Please use it with caution, as it is only providing an estimate, which will differ from what will be counted in the real API - but from our tests it comes very close.
function estimateTokens($text) {
$compactText = preg_replace('/\s+/', ' ', $text);
$textLength = strlen($compactText);
if(strlen($text) == 1) return 1; //corner case
$totalTokens = 0;
$curWordLength = 0;
$curType = 0;
for($x=0; $x < $textLength - 1; $x++) {
$curChar = $compactText[$x];
$nextChar = $compactText[$x+1];
$curType = getCharType($curChar);
$nextType = getCharType($nextChar);
if($curType == 1 || $curType != $nextType) {
if($curType == 4) {
$totalTokens += (int)($curWordLength / 6.1);
} else {
$totalTokens += (int)($curWordLength / 4.0);
}
if($curType != 4 && $curWordLength % 4 > 0) $totalTokens++;
if($nextType == 4) {
$curWordLength = 0;
} else {
$curWordLength = 1;
}
} else if($curType == $nextType) {
$curWordLength++;
} else echo '#';
}
$totalTokens += (int)($curWordLength / 4.0);
if($curType != 4 && $curWordLength % 4 > 0) $totalTokens++;
return $totalTokens;
}
function getCharType($char) {
if($char == ' ') { //is space
return 1;
} else if($char >= '0' && $char <= '9') { //is digit
return 2;
} else if(($char >= '!' && $char <= '/') ||
($char >= ':' && $char <= '@') ||
($char >= '[' && $char <= '`') ||
($char >= '{' && $char <= '~')) { //is punctuation
return 3;
}
//assume just a normal character
return 4;
}
Many developers just use a short-hand rule of thumb, which is count the number of characters and divide this by 4.
Reducing How Many Tokens You Use
The LLM is verry good at handling texts (as in words). However, we found that it treats digits and punctuation as separate tokens. If you can afford to, try removing too much punctuation, numbers, etc. Here are some examples that may surprise you:
| Text | Tokens |
|---|---|
| Hello world | 2 |
| Hello, world. | 4 |
| GPT-3.5 and GPT-4 | 11 |
| A quick brown fox | 4 |
The point should be clear: if possible avoid filler words or words with no contextual meaning if you want to minimize costs.
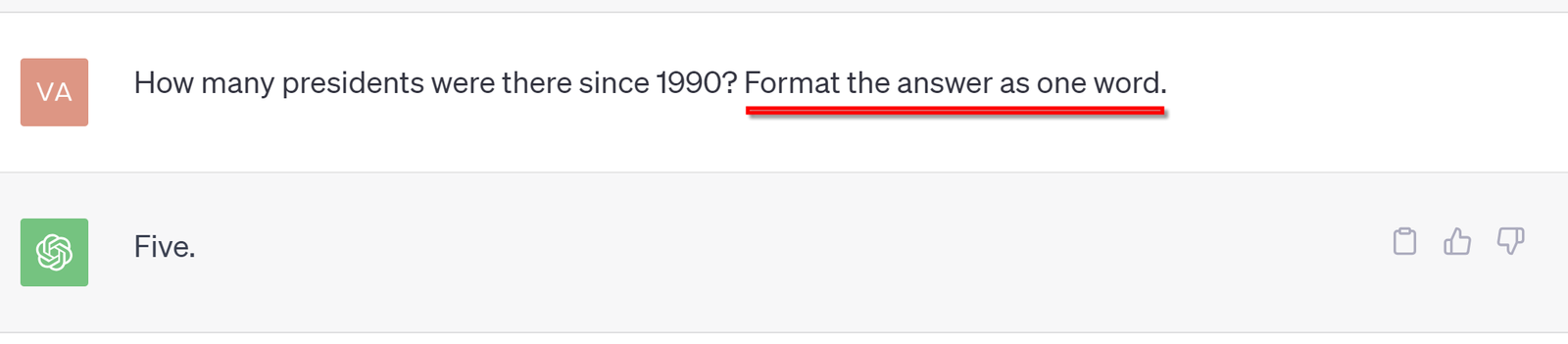
To reduce the size of the output, you may add a command (in plain text) to the prompt such as "Keep the output as short as possible", or something that makes sense for your application. See below for an example:
How To Use More Characters Than The Allowed Limit?
While we cannot really change the output maximum size, there is an opportunity to give ChatGPT more than just what is allowed. That's because this limit is only per request - but we can use multiple requests! People will often break the input into several requests, and make sure the conversation is maintained. This way, ChatGPT will have some previous texts to refer to. There are limits even to this approach however, as the model will start to forget older data and only use the most recent information.
Have a look at our ChatGPT API tutorial which comes with code examples and responses.
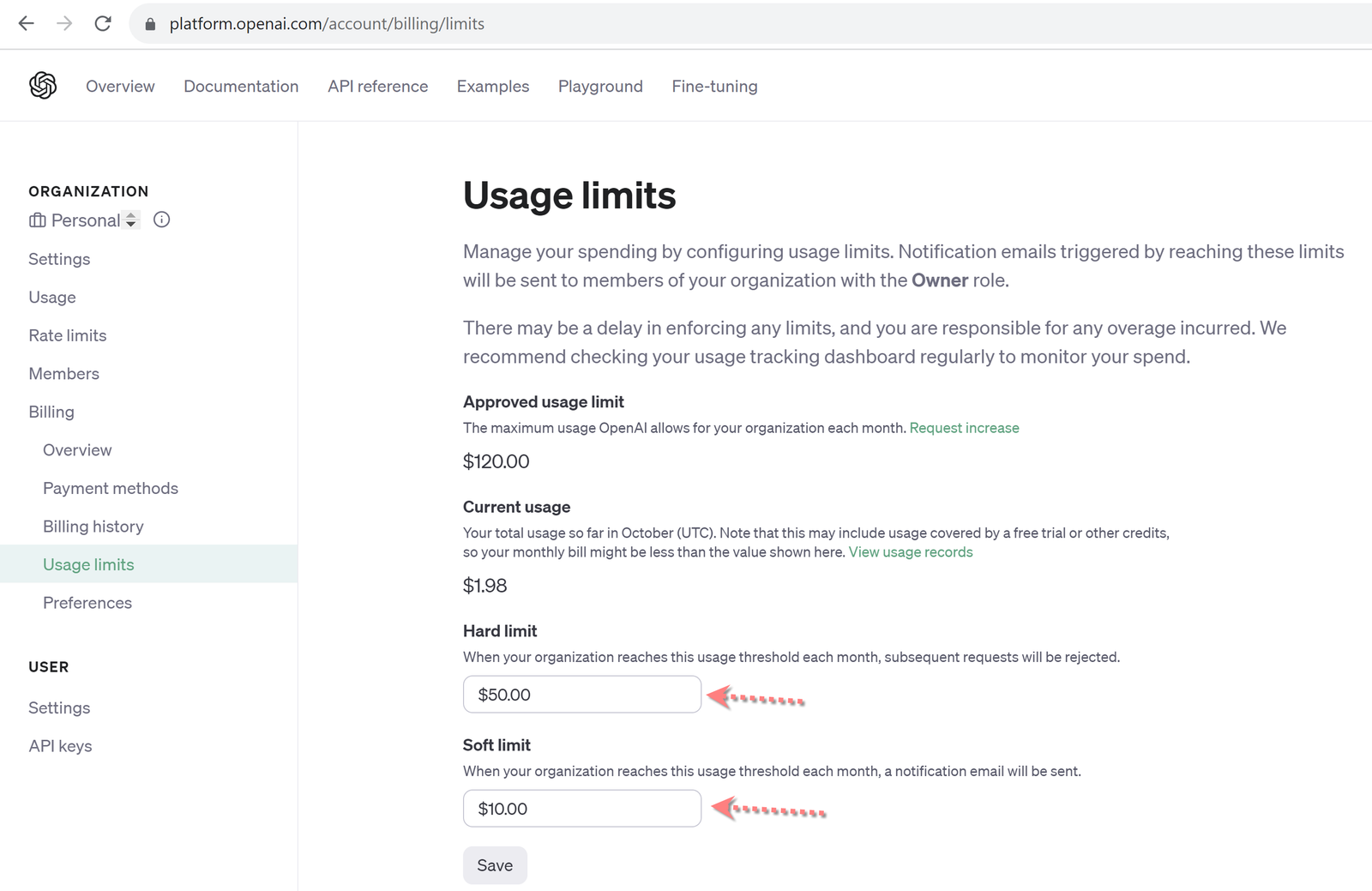
Set Your API Usage Limits
Not many companies have this feature, but OpenAI does! If you go to the page (https://platform.openai.com/account/billing/limits), there are some options to basically kill the API connection, in case it gets out of control (think accidental infinite loop). Setting some limits are a smart move, and could save you some unnecessary expenses when you're starting out or just prototyping in the ChatGPT API.
Conclusion
ChatGPT has limits on both the input and output, which are the same for a given version (3.5 or 4). GPT-4 promises to deliver twice the tokens, however this is often not seen in practice and thus far not very reliable. This should improve in the future as the models learn more over time. If you think you are ready, join the OpenAI developer waitlist, and make some plugins for ChatGPT.

















 and AI: A Business Perspective")