
OpenAI has created a large API library, which is being used by millions of developers and companies around the world. We ran performance tests for every available OpenAI API - all the way from chat to image generation and fine tuning own models. The following is a comprehensive report of all of our findings, and also suggestions for improvements in case your application is suffering from slow requests to OpenAI, ChatGPT, DALL-E, and all the rest.
Complete OpenAI API Performance Benchmarks
Below is our complete summary of the benchmarks we performed on the OpenAI APIs. In all cases, we use the following base URL: https://api.openai.com/v1
For each test, we ran a set of 10 calls, and took note of the average response times, using PostMan to make all of the connections and calls.
When testing APIs like images or chat, we made sure to create several different inputs to try an capture variability in performance. We can safely state that the OpenAI team is very nicely using parallel threads, and therefore there isn't much difference between generating one image or three.
| API | API Function | Type | Endpoint | Time ms (avg) | Model Used For Tests | Response Size |
|---|---|---|---|---|---|---|
| Models | List Models | GET | /models | 318 | ||
| Models | Retrieve Model | GET | /models/babbage | 198 | ||
| Completions (text) | Create Completion | POST | /completions | 636 | gpt-3.5-turbo-instruct | |
| Chat (text) | Chat Completion | POST | /chat/completions | 22,484 | gpt-3.5-turbo | 250 tokens |
| Chat (text) | Chat Completion | POST | /chat/completions | 31,431 | gpt-3.5-turbo | 1000 tokens |
| Chat (text) | Chat Completion | POST | /chat/completions | 14,457 | gpt-4 | 250 tokens |
| Chat (text) | Chat Completion | POST | /chat/completions | 18,974 | gpt-4 | 1000 tokens |
| Images | Create Image | POST | /images/generations | 7,882 | dall-e-2 | 1 image 1024x1024px |
| Images | Create Image | POST | /images/generations | 8,594 | dall-e-2 | 2 images 1024x1024px |
| Images | Create Image | POST | /images/generations | 8,833 | dall-e-2 | 3 images 1024x1024px |
| Images | Create Image | POST | /images/generations | 7,126 | dall-e-2 | 1 image 512x512px |
| Images | Create Image | POST | /images/generations | 7,391 | dall-e-2 | 2 images 512x512px |
| Images | Create Image | POST | /images/generations | 7,617 | dall-e-2 | 3 images 512x512px |
| Images | Create Image | POST | /images/generations | 6,569 | dall-e-2 | 1 image 256x256px |
| Images | Create Image | POST | /images/generations | 6,775 | dall-e-2 | 2 images 256x256px |
| Images | Create Image | POST | /images/generations | 7,003 | dall-e-2 | 3 images 256x256px |
| Images | Create Image | POST | /images/generations | 12,795 | dall-e-3 | 1 image 1024x1024px |
| Images | Create Image | POST | /images/generations | 16,962 | dall-e-3 | 1 image 1024x1792px |
| Images | Create Image | POST | /images/generations | 15,977 | dall-e-3 | 1 image 1792x1024px |
| Images | Create Image Edit | POST | /images/edits | 12,546 | 1 image 1024x1024px | |
| Images | Create Image Edit | POST | /images/edits | 13,441 | 2 images 1024x1024px | |
| Images | Create Image Edit | POST | /images/edits | 13,587 | 3 images 1024x1024px | |
| Images | Create Image Edit | POST | /images/edits | 9,901 | 1 image 512x512px | |
| Images | Create Image Edit | POST | /images/edits | 10,622 | 2 images 512x512px | |
| Images | Create Image Edit | POST | /images/edits | 10,978 | 3 images 512x512px | |
| Images | Create Image Edit | POST | /images/edits | 9,150 | 1 image 256x256px | |
| Images | Create Image Edit | POST | /images/edits | 9,093 | 2 images 256x256px | |
| Images | Create Image Edit | POST | /images/edits | 9,438 | 3 images 256x256px | |
| Images | Create Image Variation | POST | /images/variations | 9,885 | 1 image 1024x1024px | |
| Images | Create Image Variation | POST | /images/variations | 10,231 | 2 images 1024x1024px | |
| Images | Create Image Variation | POST | /images/variations | 10,654 | 3 images 1024x1024px | |
| Images | Create Image Variation | POST | /images/variations | 8,139 | 1 image 512x512px | |
| Images | Create Image Variation | POST | /images/variations | 8,456 | 2 images 512x512px | |
| Images | Create Image Variation | POST | /images/variations | 8,861 | 3 images 512x512px | |
| Images | Create Image Variation | POST | /images/variations | 7,302 | 1 image 256x256px | |
| Images | Create Image Variation | POST | /images/variations | 7,564 | 2 images 256x256px | |
| Images | Create Image Variation | POST | /images/variations | 7,847 | 3 images 256x256px | |
| Speech To Text | Create Transcription | POST | /audio/transcriptions | 4,011 | whisper-1 (60s audio mp3 192kbps) | |
| Speech To Text | Create Transcription | POST | /audio/transcriptions | 1,295 | whisper-1 (10s audio mp3 192kbps) | |
| Embeddings | Create Embedding | POST | /embeddings | 205 | text-embedding-ada-002 | 30-100 tokens |
| Files | Upload File | POST | /files | 711 | 10kb JSONL file | |
| Files | Get Files | GET | /files | 185 | list of files | |
| Files | Get Files | GET | /files/:file_id | 106 | single file description | |
| Files | Get File Contents | GET | /files/:file_id/content | 578 | 10kb JSONL file | single file content |
| Fine-Tunes | Create Fine Tune | POST | /fine-tunes | 247 | davinci | |
| Fine-Tunes | List Fine Tunes | GET | /fine-tunes | 231 | ||
| Fine-Tunes | Retrieve Fine Tune | GET | /fine-tunes/:fine_tune_id | 141 | ||
| Fine-Tunes | Cancel Fine Tune | POST | /fine-tunes/:fine_tune_id/cancel | 198 | ||
| Fine-Tunes | List Fine Tune Events | GET | /fine-tunes/:fine_tune_id/events | 128 | ||
| Fine-Tunes | Delete Fine Tuned Model | DEL | /models/:model | 139 | ||
| Fine-Tunes | Use Fine Tuned Model | POST | /completions | 655 | similar to normal /completions call | |
| Moderations | Check Moderation | POST | /moderations | 331 | text-moderation | 10-500 tokens |
| Engines | List Engines | GET | /engines | 175 | ||
| Engines | Retrieve Engine | GET | /engines/:engineId | 134 |
OpenAI API Average Response Times For Different Inputs and Models
How To Use The Above Performance Tests
When developing an application, it is often the case that there is slow performance in some specific area, and the dev team would need to start profiling and logging to see exactly what's happening. With the above performance metrics, hopefully this task will be easier, giving the application developers the chance to compare observed speeds with another team.
For example, if a certain API response is taking a long time, it is nice to see if anyone else has the same issue.
How The Benchmarks Can Change
We noticed that over time, OpenAI APIs are becoming faster. This is most likely due to additional hardware being commissioned to run the services, and an improving infrastructure overall.
Likewise, the exact opposite can happen in case the APIs experience a spike in requests, such as when a new product is released or big news comes out.
Why Is the OpenAI Chat API Slow?
The worst performing OpenAI API is definitely the chat completion with the conversation object. This API comes has an average response time of 22 seconds - which is a lot!
We believe the main reason for this is, the conversation object has to go through a lot of processing just to prepare the LLM context, which has to be referenced on every newly generated token. Chances are, the OpenAI team does not have much chance to improve on this, aside for getting faster machines.
How Can We Improve Our ChatGPT API Call Performance?
There are really only two options available to improve performance on the client side:
- Use buffering - this will also give the same effect like ChatGPT has, to give the result one word or token at a time
- Use the alternative API (base_url/completions) which only works on a single question/answer basis
The second option is a hidden gem, which may save many applications out there! We have a tutorial devoted to creating a fine-tuned model, and using this endpoint we got the GPT API to respond in under 0.25 seconds per request.
First, it works very fast (0.6sec per request on average). Secondly, the results are quite good. Not as good as the complete model with the full conversation - but still very respectable.
We also ran some tests of just the completions endpoint and compared the results to the chat completions endpoint, and given the performance difference we will have a serious look at changing some of our applications.
Image Generation Performance Benchmarks
On average, with the OpenAI API, we can roughly expect the following performance speeds for images:
- Generating a new image from text: ~7.5 sec
- Generating a new image, from an existing image: ~8.7 sec
- Filling an image cutout: ~10.9 sec
Depending on the output image size, performance will vary slightly, but not by a lot. So, we recommend to just work with the 1024x1024 pixel image sizes at all times.
To get the best possible performance out of the API, stick to generating just one image and in the smaller possible resolution necessary (there are three options: 256x256px, 512x512px and 1024x1024px).
As a sidenote, we can make some assumptions about how the APIs work to create images. There is one main Image Generation AI, which takes a prompt and a canvas, and fills it with content. The other two capabilities of filling cutouts and generating variations are just preparsing the input into this AI. This is only a guess, as the actual algorithms are kept in secret.
OpenAI API Unexpected Server Error
While performing tests, we can across an unexpected error, and here is what it looks like:
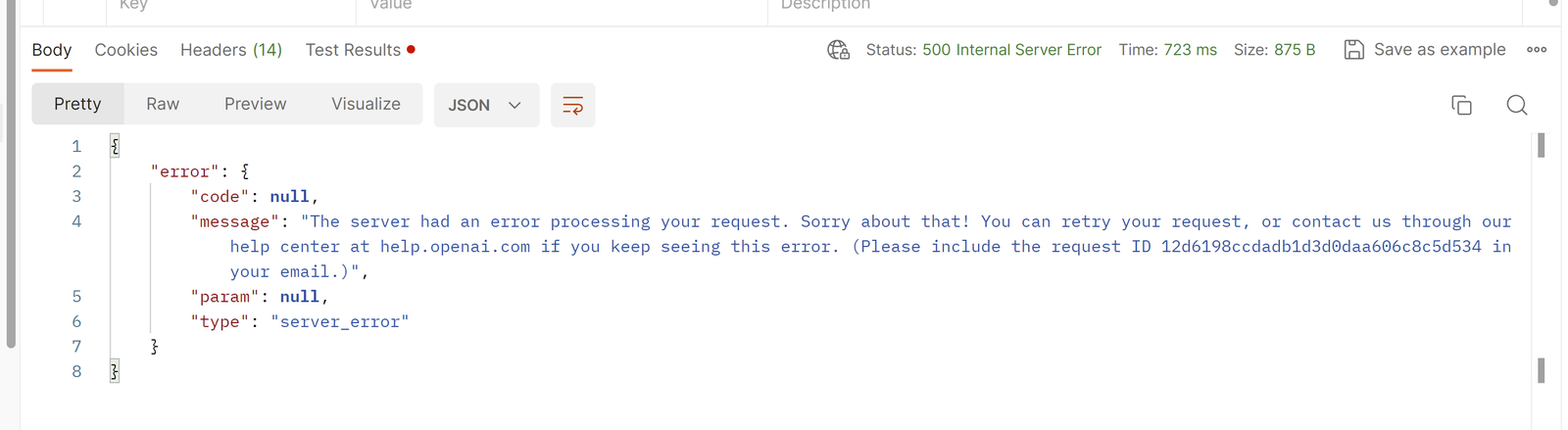
We accidentally sent an optional parameter with an empty value into the API. Hopefully this helps both the developers to catch this case, and also the OpenAI team to better handle such cases.
Which OpenAI APIs Are The Best Performers?
We firmly believe the best APIs are these: fine tuning and text completion.
These APIs specifically perform very well, under 1 second per call, and given the work done by these functions, this level of performance was actually pleasant surprise!
With these APIs, we can train custom models, and run them at amazing speeds - even faster than the main ChatGPT LLM.
What Is The Single Best OpenAI API?
We believe the Moderations API is highly underrated, and will eventually be used by all applications that use AI. It takes a single text input, and tells us if the text violates any terms of service for being unsafe for the user. Besides doing a good task, it also runs very fast and just around 0.3 sec per request.
Conclusion
OpenAI APIs are overall performing very well given the tasks at hand. It is no easy matter to generate new content on the fly, while making sure it is valuable and safe at the same time!
If you think you are ready for developing some OpenAI plugins, join the OpenAI developer waitlist, and make some plugins for ChatGPT.

















 and AI: A Business Perspective")